PintOS Project 1. Thread - WIL
웹프록시 주차 코치님 리뷰
- Rio 패키지는 왜 필요한가?
- c언어는 string처리가 어렵다. string을 제대로 공부하려면 string.h에 있는 함수들을 다 공부했어야 했다.
- 네트워크는 너무 깊게 파지 마라. 파도파도 끝이 없다. 이만큼 배웠다 해서 제대로 할 수 있을거라고 생각하지 마라
- 한 라인을 write했는데 read하는 쪽에서 한 번에 다 안 읽힐 수 있다.
→ 네트워크 환경이라서 그렇다. 패킷단위로 다 짤라서 전송하는 네트워킹 과정은 험난한 여정이다. 그래서 네트워크는 됐다 안됐다 한다.
- 퀴즈를 보니까 뭔가 공부를 더 해야겠다는 생각이 들 수 있겠는데, 결국 개발자는 코드를 짜는 사람이다. 공부도 좋지만 과제가 일순위다.
- 한국에는 입코딩이라는 단어가 있다. 아무리 많이 알고 있어도 컴퓨터에게 일을 못시키면 안된다.
- 디버깅 능력은 굉장히 중요하다.
- 무슨무슨 코드를 짜라 → 튜토리얼 수준이다. chat gpt가 코드 짜준다.
- 목표가 변경되면서 설계 고치기, 오류 발생시 고치기 → 코드 짜는 것 보다 훨씬 더 어렵고 중요하다.
- HTTP 프로토콜은 모든 개발자가 기본적으로 알고 있어야 하는 내용이다.
- 코드를 단번에 써서 단번에 성공 → 대부분 못한다. 너는 소설속의 주인공이 아니다.
- pintos 3만줄이다. → 큰 프로그램 소스를 만지는 경험도 핀토스 도입 의도 중 하나이다.
- pintos 디버그는 골치 아프다 → 디버그에 대한 내성을 길러야 나만의 무기 프로젝트할 때 버그를 잡을 힘이 생긴다.
- pintos 열심히 하면 얻어갈 것들이 많을거다.
9월 21일 목
이제 하나의 코드 저장소를 가지고 협업을 해야하기 때문에 우선 깃에 대해 공부했다.
ProGit 책 공부
1장
분산 버전 관리 시스템의 가장 큰 특징: 서버 데이터와 똑같은 데이터를 local computer들이 가지고 있음
→ 서버가 고장나도 local computer에 저장됐던 데이터 사용하면 됨
Git의 핵심: 정보를 취급하는 방식에 기존과 차이가 있음
→ 기존의 방식: 파일의 변화(델타값)를 저장하는 방식
→ Git: 데이터의 변화를 파일 시스템 스냅샷의 연속으로 취급, 크기 매우 작음

깃 방식은 로컬 컴퓨터에 프로젝트의 모든 것이 저장돼 있기 때문에, 네트워크 연결 없이 히스토리 추적 가능
깃은 데이터 저장 전, SHA-1 해시로 체크섬을 구하고, 이 체크섬으로 변화를 식별
깃은 커밋을 추가할 뿐이다.
깃의 3가지 상태

Committed: git commit을 하면 .git 폴더에 저장된다.
Modified: .git 폴더에 저장되었던 파일을 수정하고 아직 커밋하지는 않은 상태
Staged: 수정한 파일을 곧 커밋할 거라고 표시한 상태
Git directory: 프로젝트의 메타데이터 + 객체 데이터베이스 저장됨
Working tree: Git directory에 저장된 압축된 데이터베이스를 가져와서 워킹트리 만듬. 프로젝트의 특정 버전
Staging Area: Git directory에 저장되어 있음. 곧 커밋한다는 표시
- staging: 파일의 스냅샷을 만드는 것
- commited: 스냅샷을 영구적인 스냅샷으로 바꾸고 Git 디렉토리에 저장
2장
git clone
1. 자동으로 .git 폴더 만들고 이 안에 압축된 데이터 저장
2. .git 폴더 내 데이터로 워킹트리를 만들어서 가장 최신버전으로 checkout 해놓음
워킹 디렉토리 내 파일의 상태
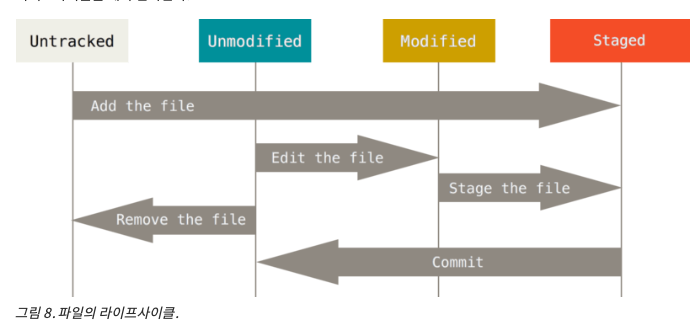
- Tracked(추적대상): .git 폴더에 스냅샷이 있던 파일 → Git이 알고 있는 파일
- Unmodified: 막 clone한 상태면 모든 파일이 다 Unmodified임
- Modified: .git에 있던 파일을 수정하면 Modified상태 됨
- Staged: 새 파일을 만들고 add 하면 staged, modifed를 add하면 staged
- Untracked(비 추적대상): Git이 모르는 파일.
Git에서 파일 삭제하는 법
- Tracked되는 파일을 없애는 것이기에, 해당 파일을 git rm 명령으로 삭제한 후, 삭제된 상태를 커밋하면 해당 파일이 Git에서 삭제됨
- 근데 그냥 파일 삭제하고 staged 해주면 똑같음
커밋 했는데 파일 하나를 커밋하는걸 빼먹었다. or 커밋 메시지를 잘못 적었을 때,
$ git commit -m 'initial commit'
$ git add forgotten_file
$ git commit --amendstaged → unstaged 방법
- 그냥 vscode에서 -버튼 누르면 됨
- 아니면, git reset HEAD <FILE>
modified → unmodified 방법(원래 막 checkout 했었던 상태로 돌아가는 법)
git checkout -- <FILE>
stash, branch 방법이 훨씬 낫다일단 Git에 커밋을 한 것이라면 언제나 복구 가능
리모트 저장소
git remote
git remote -v
git fetch <remote>: remote 저장소에서 .git 내부 파일과 대조해서 다른거(로컬엔 없는거)를 모두 .git에 받아온다
이후 git merge를 해주면 working direcoty에 파일 생성됨(그전에 로컬에서 하던거 정리 해야함)
→ git pull로 두개 동시에 처리 가능
git clone: 로컬의 main 브랜치가 리모트의 main 브랜치 추적하도록 함
git remote show origin: git push만 쳤을 때 어디로 push되는지 보여줌내가 push 하기전에 다른 사람이 remote에 push했으면, 나는 바로 push하면 절대 안됨
remote 데이터를 내 로컬에 가져와서 merge한 후 push해야함
Git 브랜치
원래 코드와 상관없이 독립적인 개발 보장
1개의 폴더가 내부에 3개의 파일을 가질 때 커밋을 하면 5개의 데이터 개체가 생긴다.
- 폴더-파일의 구조정보를 담은 트리개체 1개
- 각 파일 정보를 담은 blob 3개
- (트리를 가리키는 포인터 + 메타데이터) 개체 1개

근데, 다시 파일을 수정해서 커밋하면, 두번째, 세번째 커밋처럼 parent가 이전 커밋을 가리키게 된다.
여기서 snapshot들은 (루트를 가리키는 포인터와 메타데이터) 개체를 가리킨다


main(master) 브랜치는 자동으로 마지막 커밋을 가리킴
main 브랜치에서 git branch testing 이런식으로 브랜치를 만들면, testing 브랜치도 마지막 커밋을 가리킨다.

Git이 현재 작업 중인 브랜치가 무엇인지 아는 법
→ HEAD 포인터가 가리키는 브랜치를 보고 판단
→ 따라서 testing 브랜치도 HEAD가 가리키는 커밋(f30ab)을 가리키고 있게 된다.

git log --decorate 해주면 이렇게 뜨는데, 맨 위에 있는게 가장 최신 커밋이다.
가장 최신 커밋을 보면, HEAD는 main을 가리키고 있고, origin의 main 브랜치, origin의 HEAD, testing은 모두 가장 최신 커밋을 가리키고 있다.
git checkout testing을 실행하면, HEAD가 testing을 가리키게 된다.

그림으로 보면 지금은 아래와 같은 상태이다.

이 상태에서 커밋을 하고, git checkout main 하면 아래와 같이 된다.

HEAD는 main이 가리키고 있던 커밋을 가리키게 된다.
이렇게 되면, 워킹 디렉토리의 파일 또한 f30ab 커밋 시점으로 되돌아온다.
이제 다시 같은 파일을 수정하고 커밋하면 어떻게 될까?

이렇게 두갈래길로 갈라지게 된다.
시각적으로 보려면,
git log --oneline --decorate --graph --all
c2b9e 커밋과 87ab2 커밋을 병합할 때 필요한 개념 → 3 way merge
3 way merge: (commit1, commit2, 두 커밋의 공통조상 커밋을 합쳐서 하나로 만드는 것)
- 공통조상 커밋이 필요한 이유
- 병합 대상 브랜치의 변경사항과 병합 기준점의 변경사항 비교: 공통 조상은 병합 대상 브랜치와 병합 기준점(보통 main 또는 master 브랜치) 간의 변경사항을 비교하는 기준점 역할을 합니다. 이러한 비교를 통해 어떤 변경사항이 어느 브랜치에서 발생했는지를 정확하게 알 수 있습니다.
- 병합 충돌 해결: 공통 조상이 없는 경우, 두 브랜치 간의 변경사항 충돌을 해결하는 것이 매우 어려울 수 있습니다. 공통 조상을 통해 어떤 부분이 충돌을 일으키는지를 파악하고, 충돌을 보다 쉽게 해결할 수 있습니다.
- 병합의 일관성 유지: 공통 조상을 통해 코드의 일관성을 유지할 수 있습니다. 병합 대상 브랜치와 병합 기준점 간에 공통된 기반을 사용하면, 코드의 통일성을 유지하면서 새로운 변경사항을 통합할 수 있습니다.
- 자동화된 병합 도구 활용: 공통 조상을 기반으로 하는 병합 도구는 코드 변경을 자동으로 결합하고 충돌을 감지하는 데 도움을 줍니다. 이러한 도구는 공통 조상을 사용하여 병합 작업을 보다 효율적으로 처리할 수 있습니다.
→ 요약하면, 3-way merge에서 공통 조상은 코드 브랜치 간의 변경사항을 정확하게 비교하고 병합 충돌을 관리하는 데 필수적인 기준점이다. 이를 통해 코드 병합 작업을 보다 안정적으로 수행할 수 있다.

충돌 사항을 처리하면 다시 staged 상태가 되고, commit을 해주면 새로운 커밋이 생성된다.
git branch -v: 각 브랜치가 어떤 상태인지 확인
git branch --merged: 머지된 브랜치 리스트 확인
git branch --no-merged: 머지 안된 브랜치 리스트 확인9월 22일 금, 토
1. 핀토스 코드 중 threads.c 파일 분석

2. 핀토스 디버깅 방법
(1) backtrace - 오류 위치 확인을 위한 도구
테스트시 오류 발생하면 발생 위치와 콜스택을 출력해줌
Kernel PANIC at ../../tests/threads/mlfqs/mlfqs-block.c:28 in test_mlfqs_block(): assertion `thread_mlfqs' failed.
Call stack: 0x8004214ac7 0x800421c82d 0x80042182c8 0x8004206677 0x80042067e1 0x800420612b.kernel.o 파일이 있는 위치에서 아래 명령어를 실행한다.
backtrace 0x8004214ac7 0x800421c82d 0x80042182c8 0x8004206677 0x80042067e1 0x800420612b.결과
0x0000008004214ac7: debug_panic (lib/kernel/debug.c:32)
0x000000800421c82d: test_mlfqs_block (tests/threads/mlfqs/mlfqs-block.c:30)
0x00000080042182c8: run_test (tests/threads/tests.c:57)
0x0000008004206677: run_task (threads/init.c:252)
0x00000080042067e1: run_actions (threads/init.c:297)
0x000000800420612b: main (threads/init.c:125)위 결과를 이용해서 어디에서 문제가 발생했는지 파악할 수 있다.
(2) gdb kernel.o
1. pintos --gdb -- run <테스트명>
2. 다른 터미널 열어서 build 폴더 위치에서 gdb kernel.o
3. target remote localhost:1234
4. 브레이크 포인트 설정(ex.b test_mlfqs_block 등)
5. Kernel Panic이 발생하는 명령줄까지 가는 과정에서 값을 찍어보며 나의 예상과 다른 것들이 있나 확인. 발견시, 나의 예상과 다른 이유를 찾아 해결
9/23 토
- timer_sleep 호출
- 해당 쓰레드 블록시키고 sleep된 리스트 목록(slept_list)에 쓰레드의 엘리먼트 넣고, 쓰레드 wake_time 필드 갱신
- 매 틱마다 타이머 인터럽트 함수에서 while문을 돌면서 (현재 틱수 ≥ wake_time) 조건을 만족하면, 해당 elem에서 쓰레드를 추출한 후, thread_unblock(thread)를 해줌
9/24 일
intr_handler
- 인터럽트 OFF 상태이어야 가능
- 현재 외부 인터럽트 핸들러 수행중이면 안됨
intr_handler 브레이크 포인트 걸을 시,
- intr_entry → intr_handler → 특정 인터럽트 핸들러 수행
timer_interrupt 브레이크 걸을 시,
- timer_interrupt
- intr_entry → intr_handler → timer_interrupt → thread_tick(여기서 양보플래그 켜줌)
- intr_entry: intr-stubs.S 어셈블리파일에 있음. running thread의 intr_frame, frame_pointer, error_code, vec_no들을 스택에 넣어줌. → 이후 intr_handler() 호출해줌.
- 다시 intr_handler로 돌아온 후, 양보플래그 켜진지 확인, 양보 플래크 켜져 있으면 thread_yield 호출해서 레디큐 맨앞 쓰레드에 cpu 양보(어떻게 하는지는 밑에)
- 32번 vec_no: 타이머 인터럽트
쓰레드에 main만 있을 때, thread_yield 호출되면 우선 레디큐에 넣어주고 스케쥴링 수행한다.
이때 schedule()에서 curr은 main이고, next는 next_thread_to_run() 결과값이다. 이 함수에서 다음 쓰레드를 구하는 법은 레디큐에 있는 맨 앞 쓰레드를 빼는 것이다. 따라서 다시 main이 나오게 되는 것이다.
이후, 다음 쓰레드를 running 상태로 만들고 해당 쓰레드 틱값 초기화 해서 틱 = 0.
이제 cpu에 실질적으로 쓰레드 스위칭을 해줘야 한다.
현재, 다음 쓰레드가 같다면 굳이 스위칭 해줄 필요 없어서 패스.
다른 경우에는 thread_launch(next)를 호출해서 컨텍스트 스위칭 한다.
동작과정
처음에 main에서 init할 때,3개의 외부 인터럽트 초기화해줌
- 타이머 인터럽트(32번), 키보드 인터럽트(128), 시리얼 인터럽트(?)
PIC(programmable interrupt controller)는 자신과 연결된 I/O 장치들의 인터럽트 핀들을 가지고 있다.
이 인터럽트 핀이 켜지면 PIC는 이를 감지하여 cpu에 알린다.
cpu는 핀에 따라 상태값을 조정하여 intr_stub.S 파일 내의 intr_entry 함수를 호출한다.
타이머 인터럽트핀은 매틱마다 켜짐 → intr_entry → intr_handler(타이머 인터럽트 핸들러) → timer_interrupt → 틱++, 틱이 쓰레드 할당 틱과 같아지면 양보플래그 활성화 → 다시 intr_handler로 와서, 양보플래그 활성화 되어있으면 thread_yield() → do_schedule() → thread_launch(컨텍스트스위칭). 상태를 변경시킴 → 이제 다음 쓰레드가 running thread가 되어 작업을 수행하게 됨
kmooc OS 스케쥴링 강의 공부
스케쥴링 강의 1/4
- 리소스: 하드웨어 자원, 메인메모리의 구조체
- cpu time, disk space, network channel time 등
- 종류
- preemptive: 빼앗을 수 있는 것, 중간에 cpu를 빼앗아도 되는 리소스. 스케쥴링에도 있는 개념
- non preemptive: 빼앗지 못하는 것, 빼앗으면 중대한 영향 발생. 완전히 수행될 때까지 기다려야 하는 리소스. 마찬가지로 스케쥴링에도 있는 개념
- preemptive한 리소스를 non preemptive 로도 쓸 수 있음.
- 유리잔이 non breakable한가, breakable한가? 벽에 던진다면 breakable, 베개에 던진다면 non breakable.
- 따라서 상황에 따라 다르지만 배워두면 좋다.
- 언제나 뺏어와도 수행에 영향이 없어야 한다.
- cordinate
- 자원은 누군가에게 할당해줘야 한다. → 프로세스에게 할당
- OS: 의사 결정을 해야 함(누가 자원을 가질지)
- 또, 자원을 얼마나 오랫동안 사용해도 될지 정해주는 것
- → 2가지 종류의 의사결정
- 관리자: 프로세스 스케쥴러
- process: 생성시 ready큐,
- 프로세스의 라이프사이클: 레디상태 시간, 러닝상태 시간, wait상태 시간, i/o상태 시간
- 레디상태: preemption time. 레디큐 대기 큐잉 딜레이
- 러닝상태: execution time
- 과학기술 연산
- 사용자와 인터랙션을 별로 하지 않음
- 계산 결과를 받겠다.
- 성능척도: throughput
- 기대하는 것: throughput처리량. 단위시간당 컴퓨터가 끝낸 연산 개수
- 유저와의 interaction 중요
- response time
- i/o가 많이 일어나기 때문에, i/o
- i/o 때문에 cpu가 놀고 있으면 response가 안되는 것임
- 레디큐에 있는 스레드에게 일정 시간 cpu 할당해주는 것
- running thread가 스스로 cpu를 포기하는 것.
- waiting thread가 자기가 기대하던 event 받고 ready 상태가 되었을 때 얘가 더 우선순위 높을 수 있으니까
- 등등
- cpu scheduler가 하는 일
- time sharing operation system
- : i/o 인텐시브와 cpu 인텐시브가 섞여 있고, 두 개 각각 다른 성능척도를 만족시켜야 함
- 40ms 이상 → 적음. i/o가 그만큼 적다는 것, 과학기술 연산같은 것. cpu intensive process
- job? → 과거의 기법
- cpu burst → i/o burst → preemption → cpu burst
- CPU-I/O burst cycle
- → cpu가 리소스가 아니라 cpu time이 리소스임
스케쥴링 강의 2/4
프로세스A와 프로세스B 상태 안전한 곳에 보관 및 로딩: 스케쥴링
스케쥴링 레이턴시(디스패치 레이턴시)
: running 프로세스가 cpu 점유 끝나고 다른 프로세스가 running 시작할 때까지의 시간
scheduling policies(스케쥴링 정책, 스케쥴링 알고리즘)
스케쥴링 발생할 때: 공유자원을 여러개의 프로세스가 사용하고 싶을 때.
→ 큐를 만들어서 이 안에서 줄을 서게만든다. 줄을 어떻게 서게 하는지? → 스케쥴링 정책
정책 종류들
- first in first out: 빨리 온게 빨리 나간다
- 우선순위 기준: 우선순위가 높으면 먼저 나간다.
자기 context를 정확히 인지해서 그 시점에 가장 적절한 policy를 선택하는게 os가 하는 스케쥴링의 핵심
스케쥴링의 목표
- 리소스 이용률 최대화
- cpu와 i/o 디바이스를 최대한 바쁘게 만듬
- 오버헤드 최소화
- 스케쥴링할 때 필요한 스케쥴러 코드: nessessary evil
- 컨텍스트 스위칭 횟수 최소화
- 스위칭 할때마다 오버헤드가 들으므로
- fareness(공정성)
- cpu 사이클을 공평하게 분배
- 우선순위 스케쥴러에게는 우선순위가 높은 프로세스에게 더 많은 cpu 사이클을 주는게 공정한 것임
최적화 메트릭들
Throughout(처리량): 얼마나 많은 일을 할 수 있느냐
Response time(응답시간): i/o 인텐시브한 프로세스에서 중요
turnaround time: 프로세스 실행→끝까지 얼마나 걸리는가
waiting time: 프로세스가 레디큐에서 얼마나 기다리는가
굉장히 많이 있는 스케쥴링 policy 중 의미 있는 건 몇개 없다.
1. FIFO
batch 시스템 시절: non preemptive 방식
타임 쉐어링 시절: cpu burst까지만 사용
근데 여기에 라운드 로빈이 적용되면 timer_interrupt에 의해 time slice만큼만 사용하고 cpu 뺏기게 됨
cpu 독점 문제
time slice: 몇 틱만큼 부여받나.
단점: 동시에 프로세스 A,B,C가 들어왔고, 각각 25, 3, 3만큼 cpu burst임. 이러면 B와 C는 조금 늦게왔는데 엄청 많이 기다려야 함
convoy effect: 긴 cpu burst 프로세스가 앞, 짧은 cpu burst 프로세스가 뒤
2. SJF
3. Round Robin
4. MLFQ
스케쥴링 강의 3/4
FIFO의 아쉬운 점을 개선한(최적화한) SJF
SJF: Shortest Job First
- waiting time을 최소화한다는 점에서 optimal 정책임
- 실제 프로세스의 cpu burst를 미리 알고 있어야 사용 가능한 정책
- 이게 이상적인 거고, 이걸 통해서 다른 정책의 성능을 평가하는데 사용
Non preemptive SJF
Preemptive = shortest remaining time first
- running process의 남은 cpu burst, 다른 ready cpu의 cpu burst 비교

cpu burst 예측 기법
- Exponential smoothing
- r_n+1 = a*t_n + (1-a)r_n

잘 동작 안한다
→ SJF: 실제 컴퓨터에 적용 어려움
스케쥴링 강의 4/4
FIFO + time slice = round robin 정책
+우선순위 추가 가능
라운드 로빈 스케쥴링
너무 긴 time slice: non preemptive FIFO처럼 됨
너무 짧은 time slice: 컨텍스트 스위칭 비용 많이 듬
time slice 선택
초기 유닉스 1초: 너무 김
현재 시스템: 1~10ms (사람이 인지하기 어려운 정도), 리얼타임시스템: 500ns
최적의 time slice 찾는것 → 문제
성능 비교
RR(time slice = 1) vs FIFO
P1: burst time - 10, P2: burst time - 1
FIFO는 P2가 10초 기다렸으므로 평균 = 5
RR은 P1 1초 cpu 사용하고 P2에게 넘겨주고 P2 마무리, 이후 P1 마무리
→ (1 + 1) / 2 = 1초 평균 waiting time
근데 항상 효과적일까?
P1 = 5, P2 = 5일 때,
FIFO는 2.5초
RR는 4.5초
→ FIFO와 RR을 섞자
FIFO와 RR은 다른가?
→ NO, FIFO는 RR에 포함된다
time slice: 무한대 → FIFO
time slice: 작음 → RR
기다리는 프로세스들에 따라 FIFO, RR 중 더 waiting time이 적은 경우 골라야 함.
→ OS는 프로세스의 속성을 본 후, time slice 값을 동적으로 수정해줘야 함.
round robin 100ms time slice
p1: 1초 cpu, 10초 i/o
p2: 100초 cpu burst
p1은 1초 cpu 수행 후, i/o 할때 block됨
p1 block되면 p2로 cpu 제어권 넘어가고, 100초동안 cpu 사용
cpu 이용률: 100%
io 이용률: 10/101: 10%
round robin 1ms time slice
cpu 이용률: 100%
io 이용률: 91% io 걸리는 시간 / (다음 io시작 - 이전 io 시작)
9/25 월
priority-donate-one 테스트
main 쓰레드가 lock을 획득한다. 그리고 main 쓰레드는 두개의 쓰레드를 생성하는데, 이들은 락을 획득하고 싶어서 blocked 되었다. 그래서 그들은 lock을 가지고 있는 자기보다 낮은 우선순위인 main 쓰레드에 그들의 우선순위를 기부한다. 이후 main 쓰레드가 lock을 release하면, 기다리고 있던 쓰레드들 중 우선순위가 가장 높은 쓰레드가 해당 lock을 획득해야 한다.
시나리오
main 쓰레드가 lock을 획득한다.
main 쓰레드가 thread_create를 호출해서 acquire1 쓰레드를 만들고, acquire1은 우선순위 32이고 생성된 후 레디큐에 들어간다. 이후 main쓰레드의 할당틱 다 소진하면 acquire1이 running 쓰레드가 된다.
acquire1은 acquire1_thread_func 호출해서 lock_acquire(lock)을 호출한다.
현재 lock은 main 쓰레드가 가지고 있다. 그리고 main의 우선순위 < acquire1의 우선순위다.
따라서 acquire1 쓰레드는 자신을 해당 세마포어의 waiters에 추가하고 blocked된다.
thread_block() 호출하면 레디큐에 있던 main 쓰레드가 running 쓰레드가 되고 thread_create() 해서 acquire2 쓰레드를 생성한다.
acquire2 쓰레드는 레디큐에 들어가게 된다.
이후 main 쓰레드의 할당틱 다 소진하면 thread_yield 호출되면서 acquire2가 running 쓰레드가 된다.
acquire2는 lock_acquire(lock) 호출했고, lock이 main 쓰레드에 있기 때문에 자신을 waiters에 추가하고 blocked된다.
이제 다시 레디큐에 있던 main 쓰레드가 running 쓰레드가 되고, 마침내 lock_release(lock)을 해서 lock 소유권을 넘겨준다. 이때, 소유권을 받는 쓰레드는 해당 lock에 대한 waiters 리스트에서 가장 먼저 추가되었던 acquire1 쓰레드이다.
이제 acquire1 쓰레드는 waiters에서 빠져 나오고, thread_unblock(acquire1)이 호출되어 ready 큐에 담긴다.
main 쓰레드가 msg()를 호출하다가 할당틱을 다 소진하면 스케쥴링이 thread_yield()가 호출되어서 레디큐의 맨 앞에 있던 acquire1 쓰레드가 running 쓰레드가 된다.
그러면 acquire1은 msg(”acquire1: got the lock”)을 호출하고, 아직 할당틱이 남았으면 다시 lock_release(lock) 해서 lock 소유권을 waiters 중 맨 앞 쓰레드에게 넘겨준다.
waiters의 맨 앞에 있던 acquire2 쓰레드는 waiters에서 빠져나오고, thread_unblock되어 ready 큐의 맨 뒤에 들어간다.
acquire1 쓰레드가 할당틱을 다 소진하면 다시 thread_yield가 호출되어 레디큐 맨 앞에 있던 main? 쓰레드가 사용한다.(확인필요) 이후 다시 할당틱 다 쓰면 thread_yield 되어서 마침내 acquire2가 running 쓰레드가 되어 락을 획득하고 msg 출력 후 lock을 반납하고 msg를 출력한다.
테스트 결과

main이 acquire2 쓰레드보다 먼저 끝나서 완료 메시지를 출력하고 acquire2가 lock을 얻었다고 출력됨

이런 경우도 존재
구현 → 아래 내용은 시행착오 과정(실패)
- 레디큐에 넣을 때 우선순위를 기준으로 넣도록 한다.
- thread_unblock에서 list_push_back(&ready_list, &t→elem)로 그냥 뒤에 넣지 말고, 우선순위를 기준으로 insert 해준다.
- priority_cmp 구현완
- thread_unblock 구현완
- thread_yield에서도 running 쓰레드를 ready_list에 넣을 때 우선순위 기준으로 insert 해준다.
- thread_yield 구현완
- thread_unblock에서 list_push_back(&ready_list, &t→elem)로 그냥 뒤에 넣지 말고, 우선순위를 기준으로 insert 해준다.
- lock_acquire → sema_down
while (sema->value == 0) {
list_push_back (&sema->waiters, &thread_current ()->elem);
thread_block ();
}
sema.waiters 중 가장 앞에 있는게 가장 우선순위가 높아야 한다.
따라서 sema.waiters에 넣어줄 때 우선순위 기준 내림차순 insert 해준다
sema→value == 0일 때, 우선 락을 소유하고 있는 쓰레드의 우선순위를 파악한다.
lock 소유 쓰레드의 우선순위 < running 쓰레드의 우선순위 → lock 소유 쓰레드의 우선순위 = running 쓰레드의 우선순위 할당 → list_sort() 수행(lock 소유 쓰레드가 레디큐 가장 앞에 오도록) → 스케쥴링 수행(lock 소유 쓰레드가 running상태 되도록)
: 이러면 lock 소유 쓰레드는 자기 할일을 다 마무리하게 된다.
acquire1이 main 쓰레드의 우선순위를 높여주고 sema.waiters에 기다리다가,
acquire2가 create되어서 다시 main 쓰레드의 우선순위를 높여주고 sema.waiters의 맨 앞에서 기다린다.
근데 lock에 holder와 semaphore가 있다. 그래서 lock_acquire에서 lock의 holder의 우선순위를 보고 처리를 해준다.
- 자기보다 크면 일반적으로 수행
- 자기보다 작으면 내 우선순위를 holder의 우선순위에 기부하고 일반적으로 수행
- lock_release → sema_up
- main이 모든 ready 쓰레드들보다 우선순위가 같거나 크기 때문에 항상 스케쥴링 결과 running 쓰레드는 main이다. 그래서 lock_release(lock)까지 도달하면 소유권을 넘겨준다.
- 넘겨주는 쓰레드는 그냥 sema.waiters 맨 앞 쓰레드에게 넘겨주고(이미 우선순위 기준 내림차순 정렬되어 있기 때문에). 자신의 priority를 init_priority로 바꿔준다.
- 그전에 쓰레드 필드에 init_priority를 추가해서, 실제 쓰레드의 우선순위를 저장해둔다.
그리고 set_priority 할 때, init_priority와 priority 둘 다 바꿔준다.
get_priority할 때는 priority를 반환한다.
init_thread할 때 t→init_priority 추가한다.
9/28 목
priority-donate-one
priority-donate-multiple
priority-donate-multiple2
priority-donate-nest
priority-donate-chain
1. 위 테스트들 과정을 그림으로 그려서 문제 파악 및 구현방법 생각



2. 코드 작성 후 디버깅 과정
- list_sort 함수를 test 함수에서 돌려서 ready_list 정렬되나 확인하기
이제 정렬 적용 - →
정렬됨 - donate_one 돌려서 lock_acquire 되나 확인해보기
lock_acquire 되면 우선순위 기부됨 → 확인
- 되면 lock_release 구현
- 수도코드 써넣은 대로 구현하기
- 확인할 것들
list_sort(list): list 크기 0이나 1일 때도 작동하나 확인list_max(list): 가장 큰 요소 나오는지 확인, 비교함수를 priority_cmp 써도 되는지 확인- priority_cmp와 < > 를 반대로 적으면FIFO 우선순위 최대값 나옴
왜 list_empty에 빈 waiters 넣었는데 True가 안나오는지- if 문에 {}를 안넣어서 생긴 문제
- thread_start 할 때, next_thread_to_run() 값이 main이 나와야 하는데 idle이 계속 나옴
- 그전에, idle lock의 waiters에서 max값을 뽑을 때, main이 나오는지 확인
- 디버그용 get_thread() 만들어 사용
→ list_remove()를 써도 main이 waiters에서 remove가 안된다.- 해결완
- 그전에, idle lock의 waiters에서 max값을 뽑을 때, main이 나오는지 확인
- donate-one 돌린 결과
acquire2가 다 실행이 안되고 lock_release하면 다시 main쓰레드가 running Thread가 됨- main이 release할 때 어떻게 되나 확인
- lock_release()에서 thread_current()→priority > lock→priority로 변경
main이 acquire2 우선순위까지 기부 받고 msg 호출한 후, lock_release→list_remove 할 때 오류: (assertion(is_interior(elem) 통과 못함)- list_remove 할 때까지 가기
- 일단 list_remove() 인자에 elem 대신 donations를 넣어놨던 실수 발견
- list_remove 할 때까지 가기
lock_release할 때 list_next() 호출시 assertion(is_head(elem) || is_interior(elem) 통과 못함(헤드거나 내부면 통과하는 assertion 구문)- 확인하러 가기
- dons를 sturct list 대신 struct list*로 받고 진행 → 해결
- donate_one, donate_multiple, donate_multiple2 통과
- donate_nest 불통과
- high_thread_func → lock_acquire → list_push_back → list_insert 에서 인터럽트 걸려서 끝
- synch에서 lock_acquire 259번줄 lock에서 temp_lock으로 바꿨더니 안됨.
temp_lock = temp_lock->holder->wait_on_lock;
temp_thread = temp_lock->holder;이렇게 되어 있었음.
- 이러면 위에서 temp_lock이 바뀐 후, 밑에서 temp_lock의 holder를 참조하려고 하고, temp_lock이 NULL인 경우 NULL→holder가 되면서 페이지 폴트 → 페이지 폴트용 인터럽트 핸들러 호출되면서 종료됨.
따라서 두 코드의 순서를 바꾼다.
temp_thread = temp_lock->holder;
temp_lock = temp_lock->holder->wait_on_lock;- 남은 우선순위 테스트들
priority-donate-sema: 출력이 (priority-donate-sema)가 두번 나온 것 말고 잘됨

priority-donate-lower: 21이 41이 되어야 함

우선, 쓰레드에 자기가 보유중인 락을 담는 리스트를 만듬
priority-fifopriority-preemptpriority-sema: (priority-sema) 출력 위치가 이상함

- priority-condvar: cond 부분 구현 필요

9/29 금
priority-condvar 구현 완
→ waiters에 넣어줄 때 우선순위 기준으로 정렬되도록 넣어줘서 해결
priority-donate-sema, priority-sema 오류 해결
→ sema_up()에 thread_yield() 추가해서 세마포어 반납하면 바로 쓰레드 양보하도록 함.